Désactiver la swap actuelle
swapoff -v /dev/VolGroup00/LogVol01
Retailler le LV par exemple à 8Go
lvresize /dev/VolGroup00/LogVol01 -L 8G
Recréer l'espace swap
mkswap /dev/VolGroup00/LogVol01
Activer la swap
swapon -v /dev/VolGroup00/LogVol01
dimanche, novembre 20 2022
dimanche, novembre 20 2022. Linux
Désactiver la swap actuelle
swapoff -v /dev/VolGroup00/LogVol01
Retailler le LV par exemple à 8Go
lvresize /dev/VolGroup00/LogVol01 -L 8G
Recréer l'espace swap
mkswap /dev/VolGroup00/LogVol01
Activer la swap
swapon -v /dev/VolGroup00/LogVol01
samedi, février 13 2021
samedi, février 13 2021. Oracle
Introduction Le précédent billet présentait l'installation d'un serveur Oracle 19c en mode stand-alone. Il peut être intéressant d'utiliser ansible pour des déploiement massifs. C'est ce que détaille cet article. Le système d'exploitation est Red Hat / CentOS 7. Pré-requis Il faut dans un premier […]
jeudi, décembre 10 2020
jeudi, décembre 10 2020. Oracle
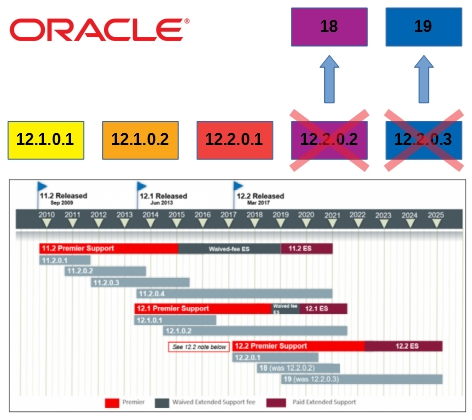
Introduction L'objectif de ce billet est de présenter la mise en place d'un serveur Oracle en stand-alone version 19c. La version 19c est en fait la version 12.2.0.3, depuis 2018 Oracle a modifié la numérotation des versions en se basant sur l'année de sortie. L'accent est mis avant tout sur le coté […]
vendredi, octobre 2 2020
vendredi, octobre 2 2020. Linux
Introduction Virtualbox est une solution très simple et gratuite de gestion des machines virtuelles. Bien que disposant d'une interface graphique, il est possible de gérer VirtualBox via la commande vboxmanage. Ce billet présente l'installation et une configuration simple de l'environnement […]
mercredi, mars 4 2020
mercredi, mars 4 2020. Oracle
Introduction La synchronisation horaire est vitale dans un cluster RAC. L'éviction de noeud peut être générée en cas de différence. Par défaut Oracle utilise NTP pour assurer la synchronisation horaire. Toutefois il est possible de laisser le cluster gérer ceci via CTSS. Ce billet présente […]
mardi, janvier 28 2020
mardi, janvier 28 2020. Linux
Comment savoir si la machine sur laquelle on travaille est un vrai serveur ou une machine virtuelle. Il existe plusieurs méthodes. Il faut disposer d'un accès root ou via sudo. Installer les packages dmidecode et facter yum -y install dmidecode facter Par la commande dmidecode dmidecode -s […]
vendredi, janvier 24 2020
vendredi, janvier 24 2020. Linux
Depuis la version 7 de Red Hat/CentOS la procédure de changement en cas de perte du mot de passe root a changé. Pour ce faire, il faut disposer d' un accès console. Redémarrer la machine et interrompre le chargeur GRUB par la touche « e ». Se déplacer sur la ligne contenant /boot/vmlinuz… Remplacer […]
vendredi, septembre 13 2019
vendredi, septembre 13 2019. Linux
Utilisation de la commande dig dig -tAXFR formation.maison ; <<>> DiG 9.9.4-RedHat-9.9.4-72.el7 <<>> -tAXFR formation.maison ;; global options: +cmd formation.maison. 38400 IN SOA ns.formation.maison. root.formation.maison. 2019071901 3600 3600 604800 86400 formation.maison. […]
mercredi, juin 5 2019
mercredi, juin 5 2019. Oracle
Introduction Dans une configuration dataguard il est intéressant d'utiliser la base standby pour procéder à un export. Ceci permet d'éviter une surcharge de la base primaire. Il faut toutefois différentier deux cas selon l'outil utilisé. EXP : Déprécié certes mais encore très utilisé. EXPDP : […]
mercredi, mars 13 2019
mercredi, mars 13 2019. Oracle
Introduction Il est parfois souhaitable lors d'un export par DataPump de modifier certaines données dites confidentielles. Un bon exemple est un numéro de carte bancaire ou de sécurité sociale. Ce billet présente l'option remap_data de la commande expdp qui permet cette transformation. La syntaxe […]
jeudi, janvier 10 2019
jeudi, janvier 10 2019. Oracle

Introduction Streams n'a pas une très bonne réputation auprès des DBA Oracle, toutefois si l'on souhaite mettre de manière simple et peu onéreuse une réplication de données entre deux serveurs, cette solution n'est pas dénuée d'intérêt. Oracle déconseille Streams au profit de GoldenGate ( coût […]
dimanche, novembre 25 2018
dimanche, novembre 25 2018. Oracle
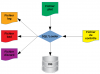
Introduction SQL*Loader est un utilitaire fourni avec Oracle permettant de charger des données dans des tables Oracle depuis des fichiers plats. Le schéma ci-dessous présente le principe de SQL*Loader. En entrée, SQL*Loader prend un fichier de contrôle ( rien à voir avec le fichier de contrôle de la […]
jeudi, novembre 8 2018
jeudi, novembre 8 2018. Oracle
Introduction Cette procédure explique comment déplacer la base _MGMTDB vers un autre diskgroup. Cette base gère les informations sur la "santé" du cluster RAC. Lors de la création du cluster cette base est créée sur le diskgroup de l'OCR soit +OCR_VOTING. Il s'agit ici de la déplacer sur […]
jeudi, juin 14 2018
jeudi, juin 14 2018. Oracle
Introduction Trois shell Linux très simples pour configurer de manière rapide et efficace la gestion des traces Oracle via ADRCI. Automatic Diagnostic Repository introduit en 11g permet une centralisation des traces Oracle en un point unique ( BD, Listener,... ). la politique de conservation de ces […]
samedi, juin 9 2018
samedi, juin 9 2018. Oracle
Introduction Ce billet, assez conséquent, détaille la mise en place d'un environnement Dataguard Oracle 12c en utilisant deux clusters RAC à deux noeuds sur des sites distants. La version de l'OS est CentOS 7.4. La version de Oracle est la 12.1.0.2 avec application du PSU de avril 2018. Il est […]
mercredi, mars 7 2018
mercredi, mars 7 2018. Oracle
Les sauvegardes et restaurations RMAN sont parfois longues et le Recovery MANager n'est pas toujours très bavard. les requêtes suivantes sont utiles afin de suivre l'avancement du processus. Cette requête permet de suivre l'avancement et surtout de déterminer une date de fin approximative. alter […]
dimanche, janvier 14 2018
dimanche, janvier 14 2018. Oracle
Introduction Dans un précédent billet il fut présenté un script de création d'une base Oracle 12c sur un cluster RAC à 2 noeuds. Ici il s'agit d'un script basé sur le même modèle mais pour la création d'une base en mode stand-alone de type non-CDB ( pas de pluggable database ). La version de Oracle […]
jeudi, novembre 16 2017
jeudi, novembre 16 2017. Oracle
Il est intéressant de connaitre la durée et le volume des sauvegardes RMAN. La vue v$rman_backup_job_details permet de retrouver facilement un bon nombre d'informations. la requête présentée ici donne le type de sauvegarde : archivelog ou base ainsi que la durée en heures et le volume. select […]
vendredi, novembre 3 2017
vendredi, novembre 3 2017. Oracle
La version 12c de oracle Database a introduit une fonctionnalité intéressante vis à vis des données dites d'archives. Il est en effet courant de stocker des milliers, voir des millions de lignes dans des tables et qui ne sont jamais ou très peu utilisées. Ceci peut être particulièrement gênant dans […]
dimanche, juillet 30 2017
dimanche, juillet 30 2017. Linux
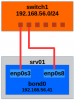
Le channel bonding ou agrégation de lien permet de configurer deux cartes réseau vue comme une seule. Chaque carte est reliée à un port du switch selon le schéma ci-dessous. L'objectif ici n'est pas de détailler la configuration channel bonding qui est largement référencée sur le Net, mais […]
« billets précédents - page 1 de 11


